Benchmarking Kotlin Collections api performance
I recently stumbled across some curious code in the Jetpack Compose source. I recommend taking a look for yourself but in summary, some google engineers had created "fast" versions of the standard Kotlin list manipulation functions for use within the framework.
/**
* Iterates through a [List] using the index and calls [action] for each item.
* This does not allocate an iterator like [Iterable.forEach].
*/
inline fun <T> List<T>.fastForEach(action: (T) -> Unit) {
for (index in indices) {
val item = get(index)
action(item)
}
}The comments elude to the fact that the standard library functions allocate an iterator which is used to traverse the content of the list. We can see this in action by decompiling some kotlin code.
fun mapList(): List {
return list.map { it * it }
}Which decompiles to
public List mapList() {
List var10000 = this.list;
if (var10000 == null) {
Intrinsics.throwUninitializedPropertyAccessException("list");
}
Iterable $this$map$iv = (Iterable)var10000;
int $i$f$map = false;
Collection destination$iv$iv = (Collection)
(new ArrayList(CollectionsKt.collectionSizeOrDefault($this$map$iv, 10)));
int $i$f$mapTo = false;
Iterator var6 = $this$map$iv.iterator();
while(var6.hasNext()) {
Object item$iv$iv = var6.next();
int it = ((Number)item$iv$iv).intValue();
int var9 = false;
Integer var11 = it * it;
destination$iv$iv.add(var11);
}
return (List)destination$iv$iv;
}It looks like an iterator is created and used within a while loop to perform the map operation. Comparing this to "fast version",
fun fastMapList(): List<Int> {
return list.fastMap { it * it }
}Which similarly decompiles to
public List fastMapList() {
List var10000 = this.list;
if (var10000 == null) {
Intrinsics.throwUninitializedPropertyAccessException("list");
}
List $this$fastMap$iv = var10000;
int $i$f$fastMap = false;
ArrayList target$iv = new ArrayList($this$fastMap$iv.size());
List $this$fastForEach$iv$iv = $this$fastMap$iv;
int $i$f$fastForEach = false;
int index$iv$iv = 0;
for(int var7 = ((Collection)$this$fastMap$iv).size(); index$iv$iv < var7; ++index$iv$iv) {
Object item$iv$iv = $this$fastForEach$iv$iv.get(index$iv$iv);
int var10 = false;
Collection var11 = (Collection)target$iv;
int it = ((Number)item$iv$iv).intValue();
int var13 = false;
Integer var14 = it * it;
var13 = false;
var11.add(var14);
}
return (List)target$iv;
}I began wondering what the actual performance gains were and decided to do some benchmarks on the JVM and Android.
Methodology
JVM benchmarks were run on a MacBook Pro (Retina, 15-inch, Mid 2014), 2.5 GHz Intel Core i7 with 16 GB 1600 MHz DDR3 with kotlinx.benchmarks. Android benchmarks were run on a Google Pixel 2 with Android 10 using androidx.benchmarks. The JVM charts were generated using https://jmh.morethan.io/. Android ops/s was estimated based on the completion time and charted using Google Sheets.
Sources used to run the benchmarks are available here.
Results
Running the JVM benchmarks yeilded the following result.
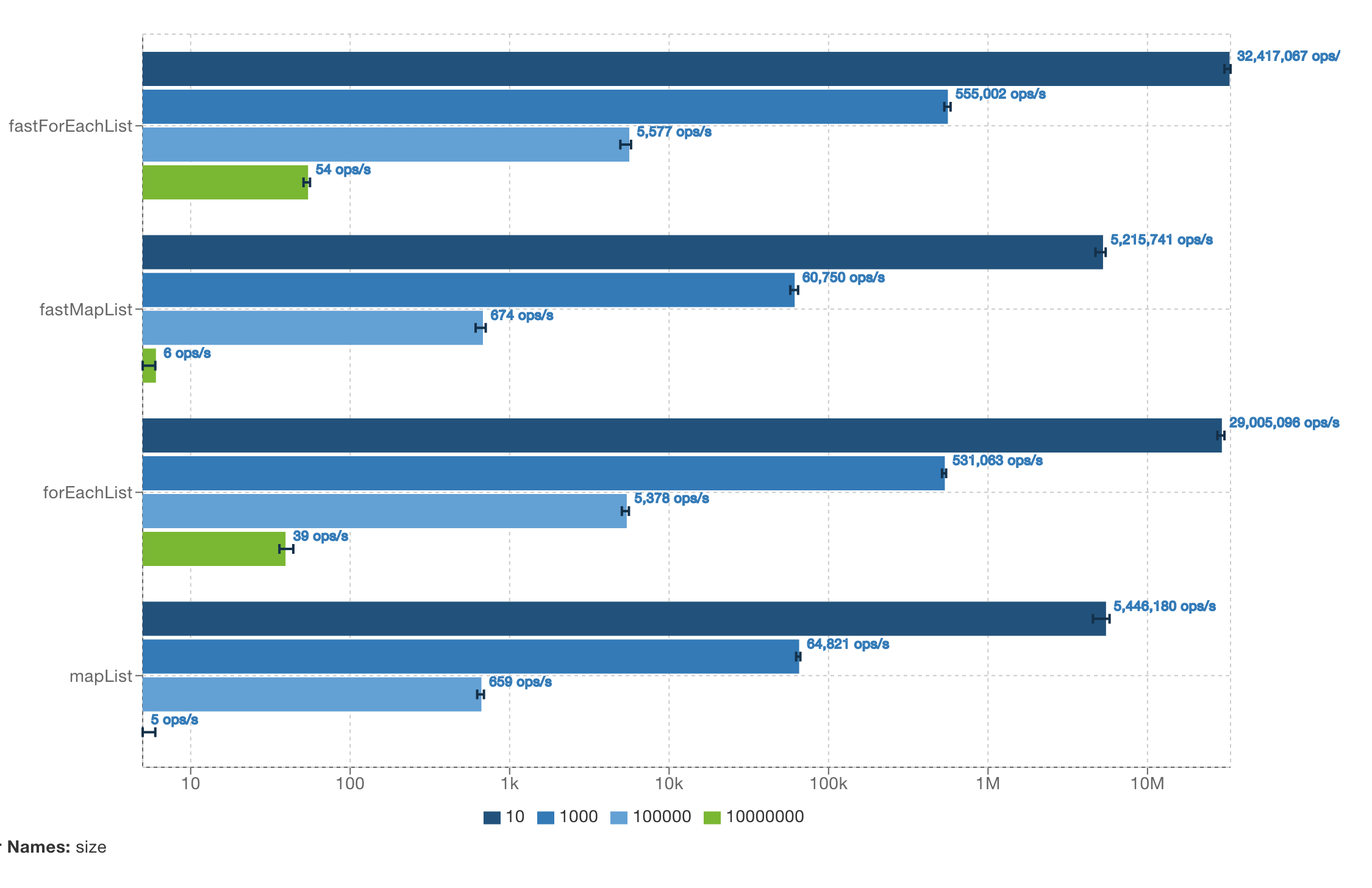
This demonstrates that some small but noticeable performance gains to be had in removing the iterator. We're seeing gains of ~3500 operations per second on the JVM for lists with 1000 items.
On Android, the results are very similar.
benchmark: 70,893,445 ns 206 allocs ListBenchmark.fastMapList_10000
benchmark: 79,759,539 ns 306 allocs ListBenchmark.mapList_10000
benchmark: 76,814 ns 200 allocs ListBenchmark.fastMapList_10
benchmark: 87,395 ns 300 allocs ListBenchmark.mapList_10
benchmark: 652,864 ns 200 allocs ListBenchmark.fastMapList_100
benchmark: 738,854 ns 300 allocs ListBenchmark.mapList_100As mentioned earlier, there are fewer allocations that are made in the "fast" versions of the functions, specifically 100 less allocations in each case. Estimating the operations per second and charting the results we see a chart similar to the JVM benchmarks.
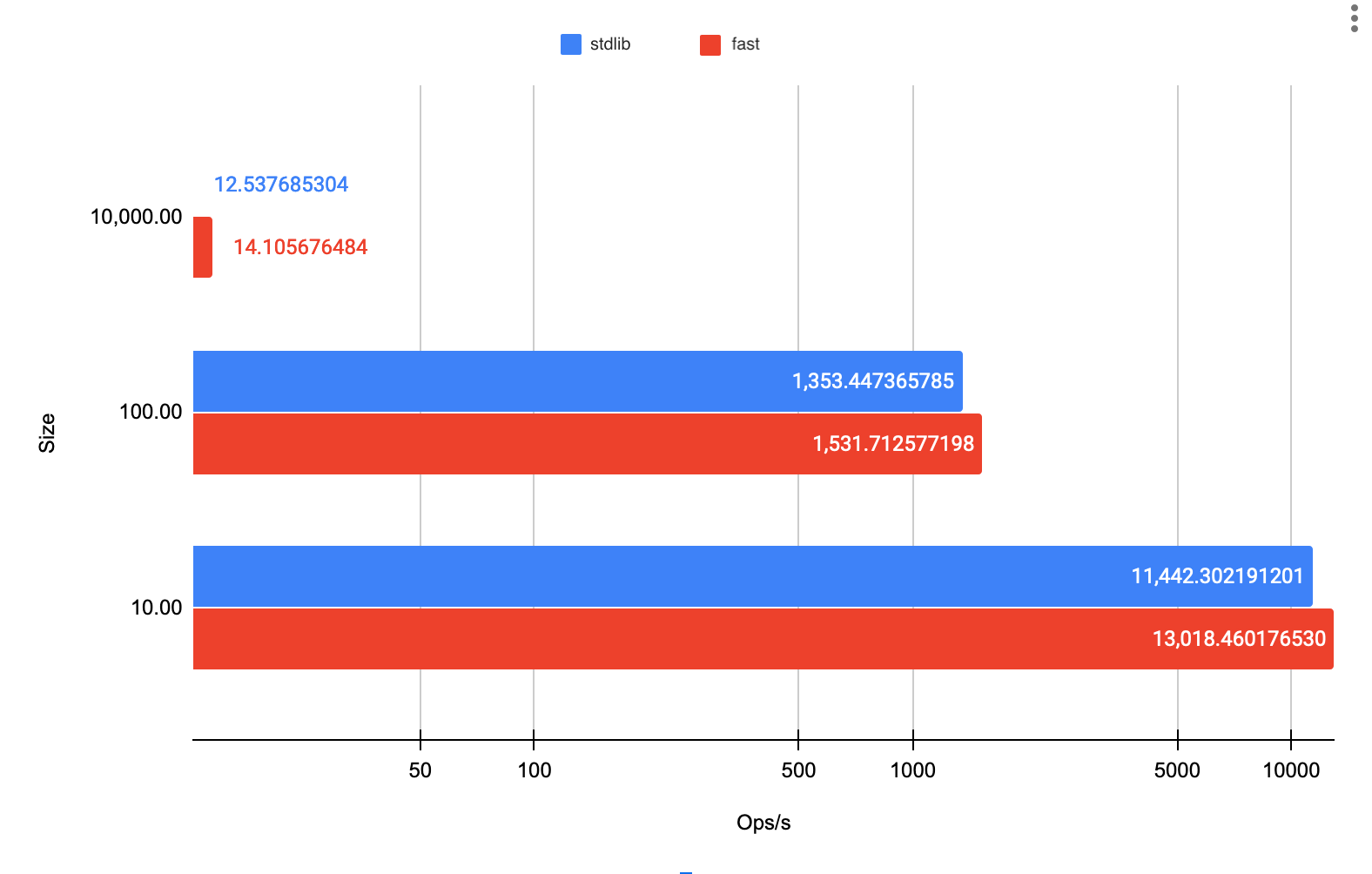
If avoiding the iterator performance generally results in faster code, why use an iterator at all? The key lies in the type of backing list. The previous benchmarks were performed on ArrayLists. However swithing the backing list to a LinkedList paints a very different picture.
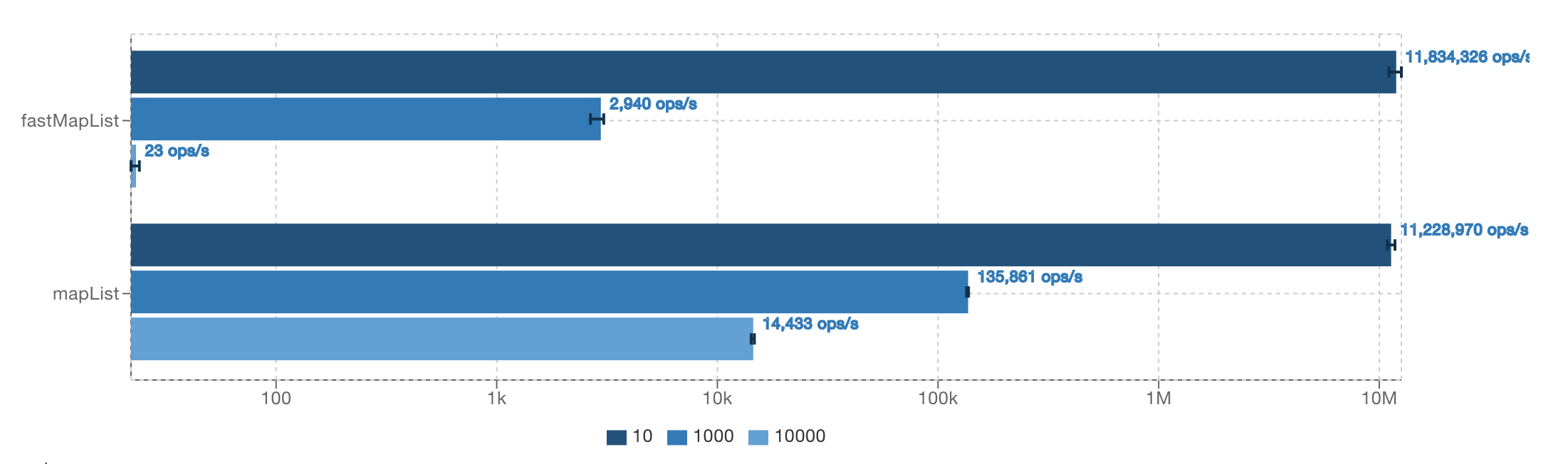
The fast versions without the Iterators are much slower than their standard counterparts. This is because collections without random access generally perform better when traversed using iterators. With an understanding of the predictable performance penalty it's best to use an iterator when you are unsure of what type of List you will be operating on.
Conclusion
While there are gains demonstrated in these benchmarks, I don't think these are significant enough to warrant setting up your own collections APIs in your projects. I'd file this under premature optimization unless you have very strict performance requirements.
These seem to have been included as part of a larger optimization effort aimed at reducing measurement performance. Exploring the larger context gives us more insight into the justification here. As these were implemented in low level parts of the compose SDK some places which may be called multiple times a second and avoiding extra GC cycles would help maintain good performance. Which means that a potential next step for these benchmarks could be to gather data on the relative frequency of GC operations triggered by the respective runtimes due to the higher amount of allocations in the stdlib version vs. their “fast” counterparts.
Remember as a general rule, you always want to understand your performance requirements and measure for bottle necks before optimizing.
Thanks to Jason Feinstein for reviewing and providing feedback on this post.